AI 语音智能体核心基础 Voice Agents
想象一下这样的场景:你打电话给一家餐厅预订晚餐,对面的声音自然、流畅,甚至会在你犹豫时贴心地给出建议——但它其实是一个 AI。这不是科幻,而是 AI 语音智能体(AI Voice Agent)正在落地的真实应用。
从教育领域的模拟面试,到商业场景的客服电话,再到医疗场景中"解放双手"的症状记录,语音智能体正在各行各业找到自己的位置。
但让 AI "说话"远比让它"打字"要难。文本对话可以容忍几秒的等待,而语音对话中哪怕多出半秒的沉默,用户就会感到不自然。延迟,是语音智能体工程化中最核心、也最贯穿始终的挑战。
带着这个核心矛盾,我们来拆解一个语音智能体到底是怎么构建的。
本文的核心知识框架来自于 LiveKit 在 DeepLearning.AI 上推出的课程 Building AI Voice Agents for Production,记录学习过程的同时,结合个人理解进行了梳理和重组。
架构路线:从 Cascade 到 Speech-to-Speech
目前实现语音 Agent 主要有两条技术路线,以及一种越来越流行的折中方案:
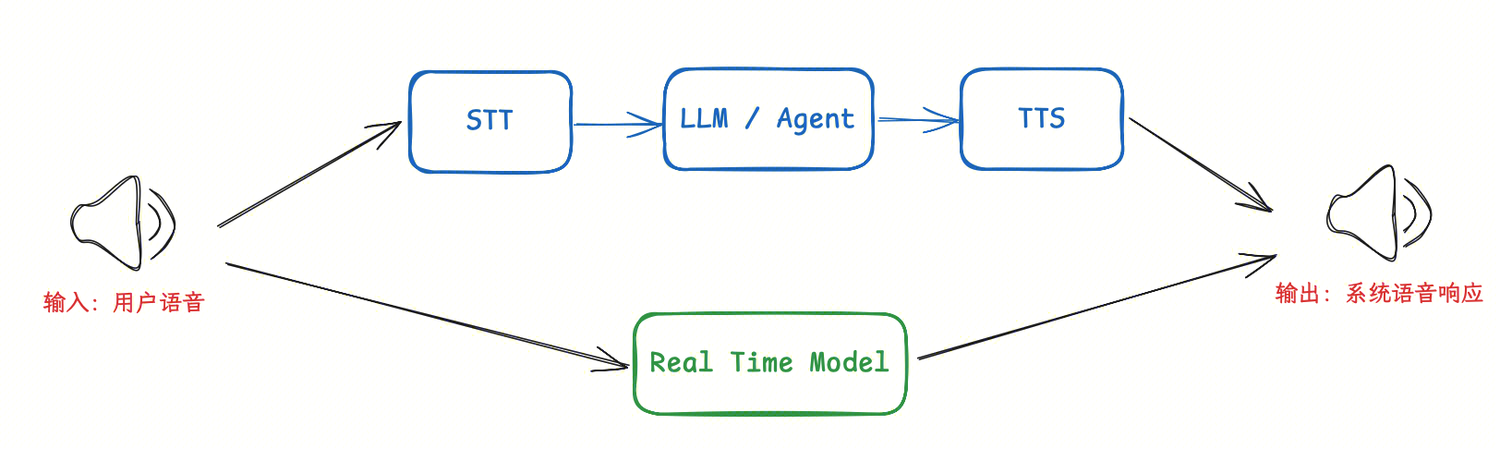
级联架构(Cascade) 是模块化的做法——把语音识别、大模型推理、语音合成等能力像流水线一样串联起来,整条管道的数据流向是:用户语音 → VAD/EOU 检测 → ASR/STT 转录 → LLM 推理 → TTS 合成 → 系统语音回复。
它的最大优势是灵活性:你可以针对不同环节选择最合适的供应商,比如在医疗场景使用专业的语音识别模型,在客服场景优化大模型的工具调用能力。代价是,每一个环节都会引入延迟,需要精细的流式处理优化。
实时架构(Speech-to-Speech) 则走一体化路线,通常使用端到端的多模态模型(如 OpenAI Realtime API)。实现简单,延迟通常更低,但牺牲的是对中间过程的控制力——你很难对某个具体环节做定制化调优。
半级联架构(Half-Cascade) 是近期越来越受关注的折中方案。它用实时多模态模型来"听"(替代传统的 ASR + LLM),但"说"的部分仍然交给独立的 TTS。输入侧享受实时模型的低延迟语音理解能力,输出侧保留对声音风格、语速、情感等维度的完全控制。对于需要品牌化音色或多语言 TTS 的场景,这往往是最务实的选择。
三条路线各有取舍,但无论选哪条,最终都指向同一个硬约束:端到端延迟必须足够低,对话才能自然。
级联架构的五大核心组件
如果你选择了级联架构(目前业界主流的生产方案),就需要理解管道中的五个关键组件。
前三个大家相对熟悉:ASR/STT(语音转文本) 负责将音频波形转录为文字;LLM(大语言模型) 是系统的大脑,根据文本生成回复;TTS(文本转语音) 再将回复转化为自然人声。
但只有这三个组件远远不够。要让 AI 能像人一样"听"和"等",还需要两个不太为人熟知却至关重要的能力:
VAD(语音活动检测) 用于实时判断音频流中是否存在人类语音,过滤掉背景噪音,确定用户何时开始说话。
EOU(话轮结束检测) 则负责识别用户何时说完了。这是一个极具挑战性的任务——人类说话时会有各种长度的停顿,系统需要区分"思考中的沉默"和"真正说完了"。
五个组件的职责可以用一张表概括:
组件明确之后,关键问题来了:这条管道串联起来,到底有多快?
延迟拆解:人类基准 vs 工程现实
先看一个基准:人类在自然对话中的平均响应时间约为 236 毫秒(研究来源)。超过这个窗口,对方就会开始感到"对面在犹豫"。
再看工程现实,把业界顶尖方案的全链路延迟拆开:
最佳情况 540ms,已经是人类自然响应时间的两倍多;最差情况超过 3 秒,用户体验会明显劣化。语音 Agent 的工程优化,本质上就是在不断逼近人类的基准。
注意,这还只是计算延迟。如果网络传输本身就慢、抖动大,实际体验会更差。这就引出了下一个关键决策——网络协议怎么选?
网络协议:语音数据如何低延迟地"进出"系统
底层:为什么语音天然适合 UDP
TCP 追求可靠性。传输语音包时,如果某个数据包(如包 2)丢失了,TCP 会等待它到达或要求重传。在这个过程中,后续已到达的包(如包 1 和 3)也无法被应用程序读取——这就是经典的队头阻塞(Head-of-Line Blocking)。对语音来说,每秒数万个音频包中只要有少量丢失,就会导致可感知的音频卡顿。
UDP 则相反,数据包到达即交付。包 2 丢了?没关系,应用程序可以先处理包 1 和 3,再自行决定如何处理缺失的部分(忽略、插值预测或直接跳过)。对于实时语音应用,UDP 给了我们在网络状况不佳时"宁可丢帧、不可卡顿"的控制权。
应用层选择:为什么 WebRTC 脱颖而出
直接基于 UDP 编程太复杂。在浏览器和移动端,实际可选的应用层协议是 HTTP、WebSocket 和 WebRTC:
WebSocket 虽然支持持久连接,但底层依然是 TCP,队头阻塞问题无法回避。
WebRTC 是目前实时音视频领域的事实标准(视频会议、语音通话等场景广泛采用),它提供了三个关键能力:实时拥塞控制自动调节发包速度,保证音频播放平滑;高效压缩将数据量降低到原始大小的约 3%;内置时间戳让 Agent 能精准判断用户何时打断了对话。
协议解决的是"语音如何低延迟地进出系统"。但要让对话真正自然,还有一层更微妙的问题——系统何时该听、何时该说、被打断后怎么办?
交互逻辑:让对话"像人"
轮次检测:AI 怎么知道你说完了?
在人类对话中,判断对方是否说完了是本能。但对 AI 来说,这需要精巧的轮次检测机制。
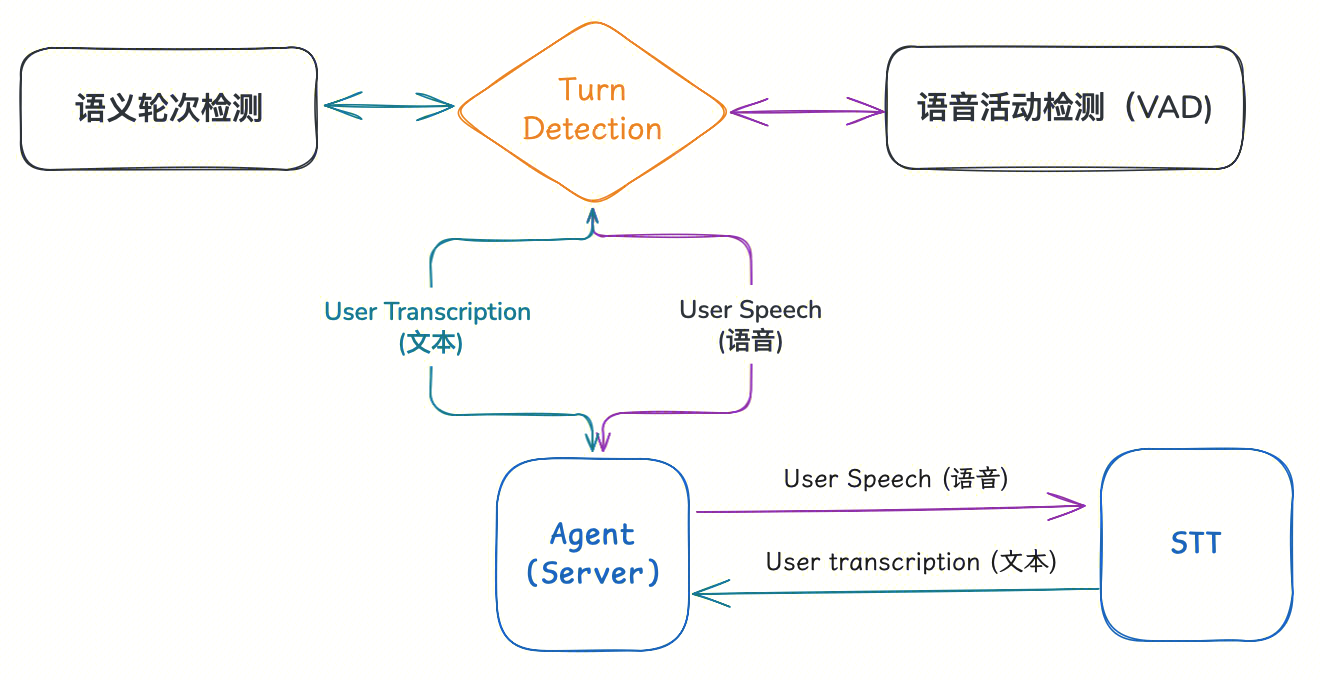
现代系统通常结合两种信号来解决这个问题:
信号层:语音活动检测(VAD)。 VAD 是一个小型二分类神经网络,只回答一个问题:"现在有没有人在说话?"当 VAD 从"检测到人声"变为"静音"时,会启动一个可配置的毫秒级计时器。如果计时器结束前没有新的人声,就触发"轮次结束"事件。
语义层:话轮结束检测(EOU)。 单纯靠 VAD 不够——人说话时经常停顿思考,如果每次停顿都被当作"说完了",体验会很糟糕。EOU 通常使用一个 Transformer 模型(比如基于 BERT 的模型)来辅助判断:它分析当前转录文本和前几轮对话上下文,如果判断用户只是在停顿而非说完,就会延迟 VAD 的计时器,防止 Agent 粗鲁地"抢话"。
打断处理:用户不想听了怎么办?
真实对话中打断随时发生,Agent 必须能优雅地处理。
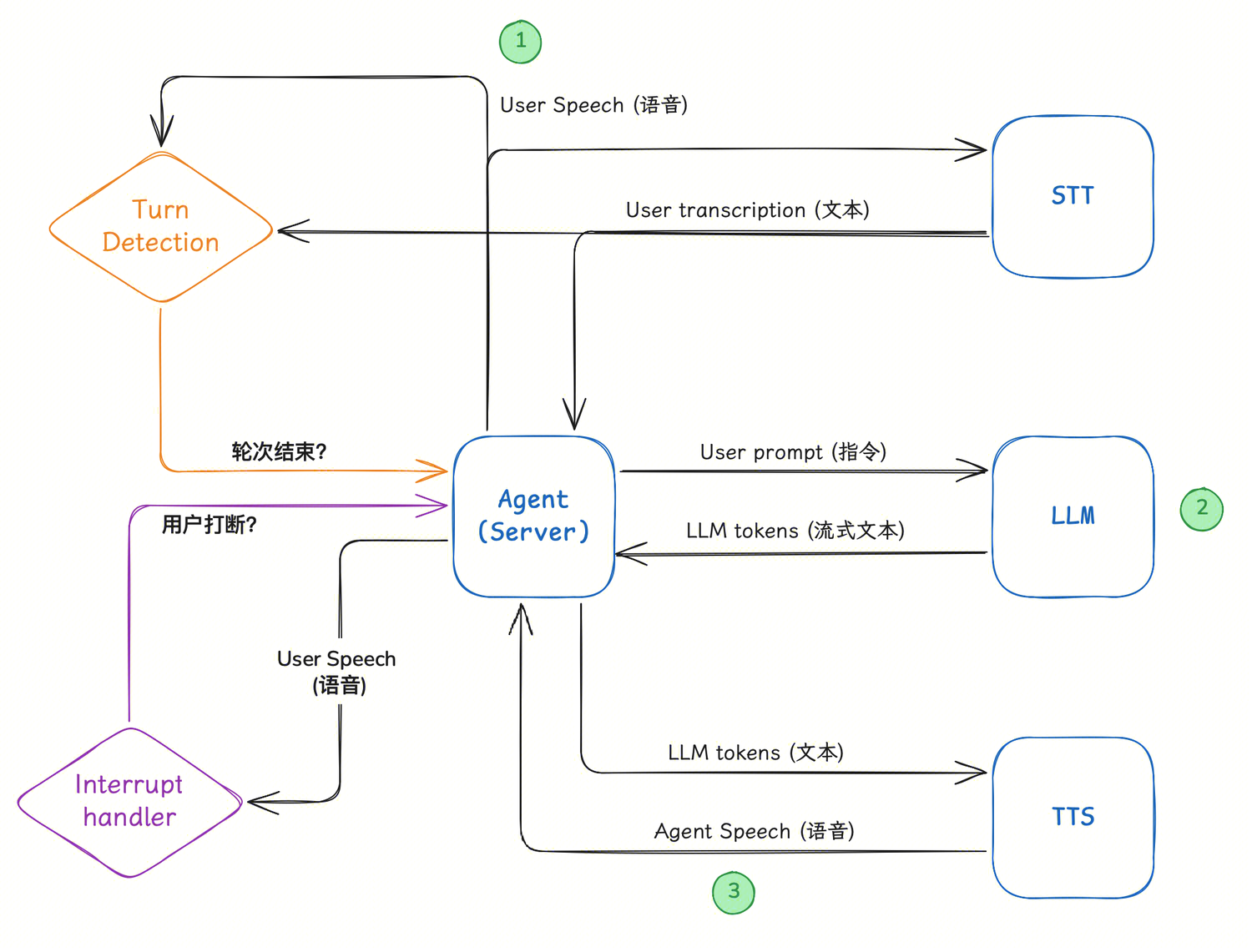
由于用户的语音始终经过 VAD 监控,一旦在 Agent 说话时检测到用户发声,系统会立即识别为打断,并触发一系列清理动作:LLM 停止推理、TTS 停止生成、播放缓冲区清空。
上下文对齐:打断之后不能“失忆”
打断处理还有一个容易被忽略的细节:Agent 说到一半被打断,用户实际听到了多少?
生产级语音 Agent 架构会引入专用的上下文管理器来解决这个问题。它不仅维护完整的对话历史(包括 Function 调用结果),还会在打断发生时,通过时间戳计算用户实际听到的内容,据此对齐 Agent 侧的上下文,确保下一次回复逻辑连贯、不"断片"。
完整架构一览
把上面所有模块拼在一起,就是一个生产级语音 Agent 的完整架构:
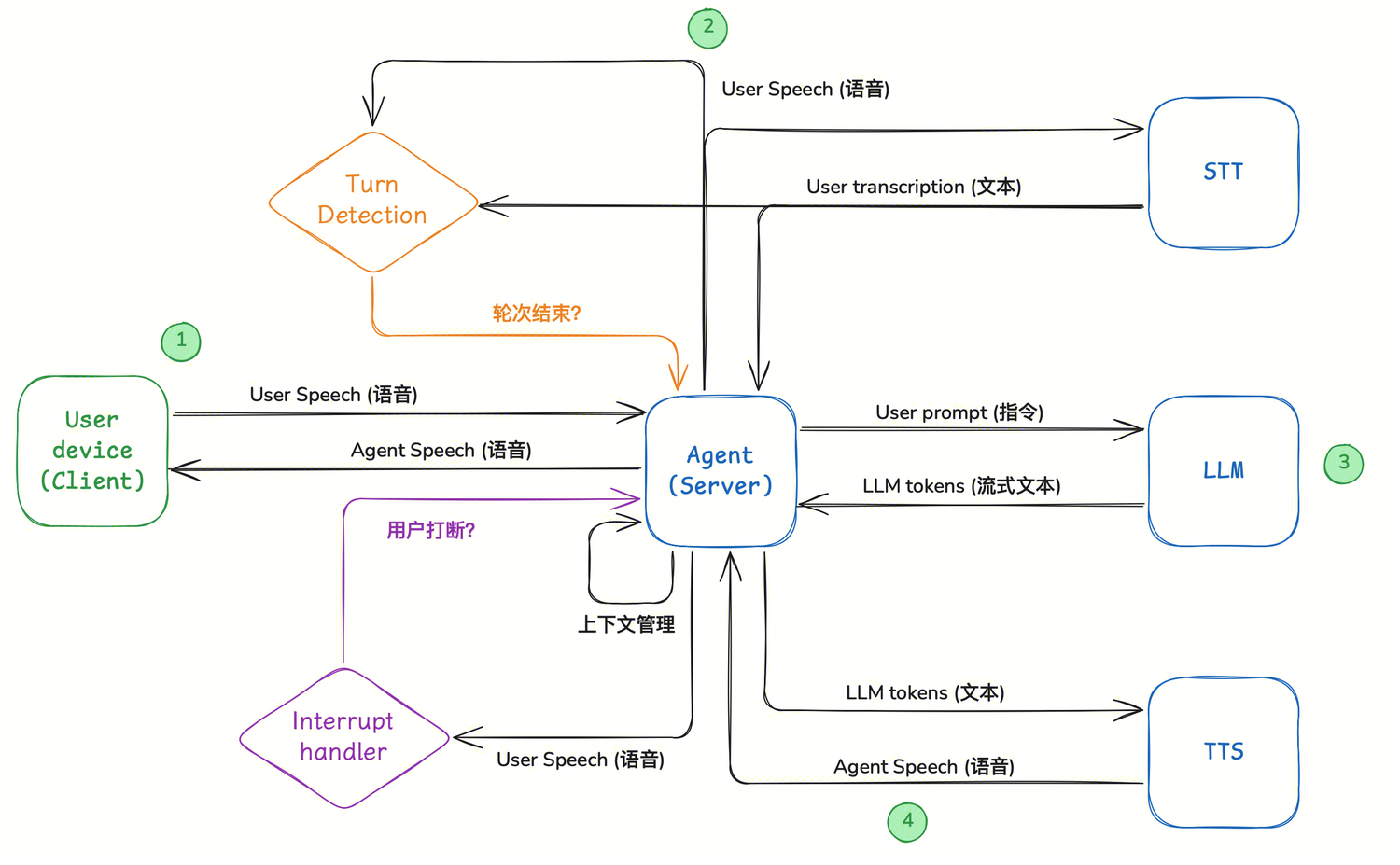
从用户语音输入开始,经过 VAD 检测、ASR 转录、LLM 推理、TTS 合成,到语音输出——每一环都在和延迟赛跑,同时轮次检测、打断处理和上下文管理在背后协调,保证对话的自然流畅。
走向生产:还有哪些硬骨头?
有了可运行的架构,离真正上线还有距离。生产环境会暴露出一系列在 DEMO 阶段不易察觉的问题:
转录噪声与语音伪影。 人说话不是打字——停顿、口头禅("嗯""那个""就是说")、背景杂音都会被 ASR 忠实地转录下来。这些"噪声文本"不仅污染 LLM 的输入,还会干扰 EOU 的判断:一句"嗯……"到底是在思考,还是已经说完了?目前常见的做法是训练 EOU 模型对这类口语模式做针对性的鲁棒性优化。多语言场景下问题更突出——多语言 ASR 的准确率通常明显落后于单语言模型,转录噪声会被进一步放大。
LLM 是延迟的最大瓶颈。 在级联架构的全链路中,LLM 的首字延迟往往占到总延迟的 40% 以上。优化方向取决于部署方式:自托管可以用量化后的模型来换速度;调用第三方 API 则需要关注限流策略和服务商的推荐配置。还有一个常被低估的杠杆是 Prompt 工程——通过约束让 LLM 回复更简短,或采用"先给一句确认、再输出完整回复"的分段策略,可以显著降低用户感知到的等待时间。
延迟的可观测性本身就是难题。 客户端测量的延迟和服务端测量的延迟往往对不上——网络抖动、音频缓冲、设备性能都会引入差异。没有准确的度量,优化就是盲人摸象。生产级系统通常需要在管道的每个节点埋入时间戳,建立端到端的 tracing 能力,才能定位真正的瓶颈在哪里。
写在最后
AI 语音智能体的核心,不是"把 ASR、LLM、TTS 串起来"这么简单。它本质上是一场围绕实时性的工程战役:架构选型、协议选择、轮次检测、打断处理、上下文对齐——每一个决策都在回答同一个问题:如何在延迟约束下,让机器的对话尽可能像人。
这条路还很长,但基础设施正在快速成熟——端到端模型持续压低延迟下限,半级联架构让灵活性和速度不再二选一,WebRTC 等实时传输层也已经是开箱即用的状态。剩下的,更多是工程细节上的打磨。
参考资料
- LiveKit & DeepLearning.AI, Building AI Voice Agents for Production
- Stivers, T. et al., Universals and cultural variation in turn-taking in conversation, 2024

微信公众号「NPC菌」
更多 AI 与工程实践的深度拆解,扫码关注即可订阅